Git worktrees and pyenv: developing Python libraries faster
It’s glorious to work on one task at a time, to be able to take it from start to finish completely, and then move onto the next one. Sounds great, but reality is messier than that and context switches are common. Doing so can be annoying and inefficient, but not switching means tasks and colleagues are delayed. I combine git worktrees and pyenv (and plugins) to reduce the overhead of a context switch and keep development and collaboration as smooth as possible when working on a Python library.
Reducing the pain of a context switch allows me to work on many tasks concurrently: usually one or two large features with a few medium ones and a variety of small ones. My day typically involves working on the larger features for hours consecutively, and then either getting blocked or needing some time to think subconsciously, and thus pick up one of the smaller tasks.
Context
This post talks about how I use these tools in practice, in my work on the StellarGraph library for machine learning on graphs. StellarGraph is a Python library built using TensorFlow 2, Keras and other common data science tools.
We take a fairly standard approach to developing and distributing the code, which means promptness and collaboration are important:
- extensive demos and documentation
- supporting multiple versions of Python (3.6 and 3.7)
- all changes happen via pull request (with 70-100 per month)
- code review is required: a pull request cannot be merged without at least one approving review
- testing is also required: a pull request cannot be merged without passing continuous integration, including validating the demos (which all adds up to take a few minutes)
The StellarGraph team is a project of CSIRO’s Data61 that brings together engineers, data scientists, UX designers and researchers. I mostly fit into the first of those boxes and part of my role as an engineer on a mixed team is being a force multiplier: optimising or otherwise making the code more reliable, and improving the tooling & processes listed above (and others), all so that others with less engineering experience or more research interest can use their strengths best.
This means my day is often broken up with:
- reviewing others’ pull requests, so they’re not waiting for approvals and feedback; this sometimes involves checking out the pull request’s code locally to run it
- responding to code reviews on my own pull requests, to try to keep the “review cycle” as tight as possible; this usually involves editing the code in response
- doing small fixes for annoying paper cuts
- validating requirements and expectations for larger or more complicated features and bug fixes; this often involves doing a proof-of-concept implementation as a draft pull request
All of these involve working with the repository’s code on my local machine, and all of them are typically short tasks, ranging from minutes to hours, not days like a new feature.
In addition to all of these code tasks, when I do finish a feature or bug fix, I then have to wait for code review from one of my colleagues: this is usually fast (at most a day or two), but, if I was trying to avoid context switching, it’s a long time to do no other work.
Sequential development
Suppose I’m working on feature A, but then notice paper cut B that would take a minute or two to fix, maybe a typo in documentation or a minor bug. This is something like the third situation above.
One approach is to just do the fix in the changes for feature A, so that the eventual pull request and code that lands combines both A and B. This is suboptimal, as it leads to:
- Slower code reviews: each review is larger, and it’s unclear what change was for what purpose so more detangling is required.
- Less useful git history: if the combined A+B change appears in a
git blameinvestigation, it’s just like looking at it in a code review except the author likely can’t answer questions about it, because they no longer remember (I certainly forget these sort of details quickly). - Slower landing of the useful small fixes: the fix for B gets caught up and delayed by the lengthier review of the A’s pull request.
A better approach is to do this work on a separate branch, and thus in a separate pull request. Doing this concurrent work with a single copy of a repository is frustrating, because the book-keeping work required to do the fix dwarfs the actual effort to fix:
- Save the state of my work-in-progress work on A’s branch
feature/A, which means both:- the actual changes to files on disk (either with a “WIP” commit or stash, taking care to manage any relevant temporary or new files)
- any context that’s not directly stored in version control (such as where I’m editing in each file, or what I’m planning to do next)
- Create and switch a new branch
bugfix/B, do the fix for B, create a pull request for it - Restore the A work, by switching back to the
feature/Abranch and then reapplying/remembering any other state from step 1
The actual fix, step 2, is much easier and even faster than either of steps 1 or 3, which require remembering things about the code base while also remembering things about git (hard work!).
Concurrent development
The list is much simpler if I have multiple parallel copies of the source code, each of which can be changed independently:
- Change from the directory that has
feature/Achecked out to one that doesn’t have any work-in-progress work (or create a new copy) - Create a new branch
bugfix/B, do the fix for B, create a pull request for it - Change back to the directory for
feature/A, picking up where I left off (including things like the exact position for each file in my editor)
The whole process takes about as long as step 2 itself because there’s little book-keeping. It doesn’t directly fix the “remember what I’m planning to do next” problem from the first version, but it does dramatically improve it: I find there’s minimal context switching from a “work on the code” mindset to a “manage git” one, and there’s less time to forget or get distracted because the whole process is faster.
Using separate directories has other benefits over switching branches too: it makes it easier for incremental compilation (and other tooling) to reduce work, although this doesn’t apply to Python so much0; and, I find it’s easier for me to find my code1.
One way to implement this is to clone the repository multiple times into separate directories, like ...-1, ...-2 and so on:
1
2
3
git clone 'git@github.com:stellargraph/stellargraph.git' stellargraph-1
git clone 'git@github.com:stellargraph/stellargraph.git' stellargraph-2
git clone 'git@github.com:stellargraph/stellargraph.git' stellargraph-3
I used this effectively for many years for a few different projects.
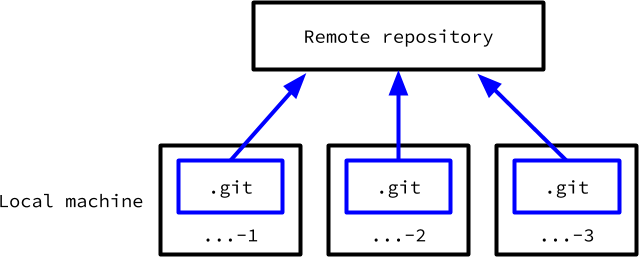
A stylised view of the structure of multiple clones of a single repository shows they are isolated from each other.
However, each copy is isolated, which leads to some problems in practice:
- They each require the full git state, which is potentially large.
- They can end up with inconsistent state, especially about remote branches:
origin/masterinstellargraph-1may be different toorigin/masterinstellargraph-2, depending on whengit pullorgit fetchwas run. - There can be confusion about “where was that branch”, whenever I do switch away from a branch, because, by default, each branch only exists in the copy where it was created.
Concurrent development with worktrees
A better way is to use multiple worktrees. These behave almost identically to multiple independent clones, except they share a single .git directory with all its metadata. Therefore, each one has access to all branches (local or remote) and the state of each of those branches is the same in every copy.
A worktree can be created in a single command2, similar to a git clone:
1
2
3
4
5
cd /path/to/stellargraph-1
# now inside the repository that needs multiple copies
git worktree add ../stellargraph-2 'some-existing-branch'
git worktree add ../stellargraph-3 -b 'some-new-branch'
The first argument to add is the (sibling) directory for the new worktree, and the second optional one is the name of the branch to checkout there (to start with). Each of these stellargraph-... directories acts like a normal git repository, and all the usual operations like creating or switching branches, committing and stashing work just fine.
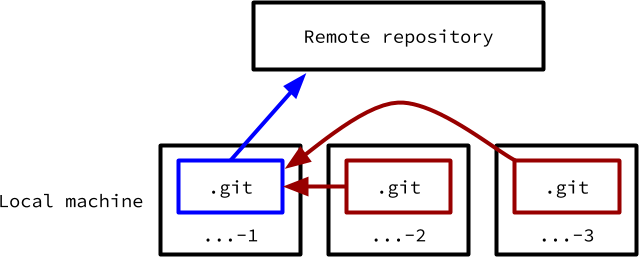
The stylised view of worktrees shows that they all share a single main .git folder.
I use a fixed set of worktrees, numbered from 1 to 5 (at the moment).
An alternative (that I’ve never tried) is to have a worktree for individual branches. If we’re starting a new feature in a new branch foo, the system might look something like the following:
1
2
3
4
5
6
7
8
9
10
git worktree add ../stellargraph-foo -b foo
cd ../stellargraph-foo
# edit code...
git push
# (repeat from 4 until finished)
# finished, so the worktree isn't needed any more
cd ..
rm stellargraph-foo
I’ve used worktrees on all sorts of projects, including Scala, C++ and Rust. Python brings some special challenges.
Parallel Python dependency management
Multiple copies of a source tree is great, but also leads to some confusing circumstances if the state is mixed up. It can be easy to edit a file in the wrong directory, and then not understand why it’s not applying. I know I’ve spent time tracking down incorrect-location edits whenever there’s multiple copies of anything (functions, files, directories, …)!

Dependency management is hard enough, without having to do 5 times at once
Python’s common approach to dependencies makes this worse: code needs to be run in the correct virtual environment, which is, by default, managed separately to the current directory. Typically, each checkout would have its own virtual environment, in case there’s differences in the exact set of dependencies used, and to allow each copy to install its exact on-disk version of StellarGraph with --editable.
A sequence in a terminal might look like:
1
2
3
4
5
6
7
8
9
cd .../stellargraph-1
. venv/bin/activate
# do work, like running tests:
pytest tests/
# finished there, let's move
cd ../stellargraph-2
# run tests again
pytest tests/
Unfortunately, I’ve made a mistake there: the pytest run on line 9 is running with the virtual environment from the stellargraph-1 worktree, not properly reflecting the state of the stellargraph-2 source tree. I needed to run . venv/bin/activate again after the cd on line 7, using the venv directory in stellargraph-2.
pyenv to the rescue
I solve this by using pyenv and pyenv-virtualenv. Instead of creating a virtual environment in each worktree (such as in a venv subdirectory), I create a pyenv virtual environment for each one and associate them using pyenv local. For example, for the stellargraph-1 worktree, I ran something like:
1
2
pyenv virtualenv 3.6.10 'stellargraph-1'
pyenv local 'stellargraph-1'
After doing this, any command that uses python or pip (like pip install --editable . or pytest) anywhere within the stellargraph-1 worktree will automatically use the stellargraph-1 virtual environment3: I don’t need to manually activate or deactivate the virtual environments, cutting out a major piece of human error.
Using pyenv for version management has other benefits too:
- pyenv-jupyter-kernel allows for automatically registering each virtual environments with Jupyter, making it easy to test features and bug fixes in a notebook, and, more importantly, work on StellarGraph’s demos.
- virtual environments can be easily created for different versions of Python (replace
3.6.10with3.7.7). For instance, I havestellargraph-1-3_7to also test/compare with Python 3.7 in thestellargraph-1worktree (I do not use these ones withpyenv local, justpyenv shell, which does require manual activation and deactivation).
Wrapping up
I use git worktrees to have parallel copies of the StellarGraph Python library that share git metadata, and pyenv & pyenv-virtualenv to manage the Python virtual environments for each. This reduces the overhead of switching contexts, and so makes it easier for me to do more work and collaborate efficiently, by fitting small fixes into the gaps around big features.
-
Switching branches will update the contents of files on disk, which looks like a modification of those files, even if all of those changes were undone when restoring the original files in step 3. Tools that monitor for modifications to reduce work will get confused by the “switch, …, switch back” and spuriously do more work: separate directories avoids this entirely
Many Python projects (including StellarGraph) don’t need to worrying about to refreshing/rebuilding state associated a source tree, because they often don’t have any compiled artifacts or other generated state associated with a branch. The code runs directly from the source files, without any compilation or preprocessing.
In a compiled languages like Scala or C++, I’ve found this benefit much more important: builds are much faster when they can be incremental, just updating the artifacts associated with the (small number of) source files that I actually changed. If switching branches and then back spuriously modifies-then-unmodifies a lot of files (or a file with a lot of dependents), the first build after doing that may be much slower than an incremental build for the real changes, without any branch switching. ↩
-
I always forget to delete branches after finishing with them, so I end up with dozens (or hundreds…) of local branches associated with closed and merge pull requests. These interfere with tab completion, requiring me to remember a significant amount of the name for
git checkout .... I find it’s easier to remember which of a handful of checkouts holds the relevant code, and even when I do forget, a brute-force approach of checking every copy is fast (skipping ahead, this is even faster with worktrees, withgit worktree list). In some ways, this benefit is treating a symptom, not the disease… but it works for me. ↩ -
I usually use git via magit in Emacs, where these creation commands are
% bor% cin the magit status buffer, and jumping between worktrees is% g(relevant docs). ↩ -
Using pyenv for virtual environments is great for working on multiple separate libraries/code bases, even without multiple copies. The process is exactly the same:
pyenv virtualenv ...to initialise the environment, andpyenv localto associate a directory with the virtual environment. ↩