SIMD in Rust
A new scheme for SIMD in Rust is available in the latest nightly compilers, fresh off the builders (get it while it’s hot!).
For the last two months, I’ve been interning at Mozilla Research, working on improving the state of SIMD parallelism in Rust: exposing more CPU instructions in the compiler, and an in-progress library that provides a mostly-safe but low-level interface to that core functionality.
It’s still simple to use; the following are kernels for rendering the Mandelbrot set, one scalar, one with explicit vectorisation, and both similar:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// Scalar!
// compute the escape time for the point `c_x + i c_y`
fn mandelbrot_naive(c_x: f32, c_y: f32, max_iter: u32) -> u32 {
let mut x = c_x;
let mut y = c_y;
let mut count = 0;
while count < max_iter {
let xy = x * y;
let xx = x * x;
let yy = y * y;
let sum = xx + yy;
if sum > 4.0 {
break
}
count += 1;
x = xx - yy + c_x;
y = xy * 2.0 + c_y;
}
count
}
// SIMD!
// compute the escape time for the four point `c_x + i c_y` at once
fn mandelbrot_vector(c_x: f32x4, c_y: f32x4, max_iter: u32) -> u32x4 {
let mut x = c_x;
let mut y = c_y;
let mut count = u32x4::splat(0);
for _ in 0..max_iter {
let xy = x * y;
let xx = x * x;
let yy = y * y;
let sum = xx + yy;
let mask = sum.lt(f32x4::splat(4.0));
if !mask.any() { break }
count = count + mask.to_i().select(u32x4::splat(1),
u32x4::splat(0));
x = xx - yy + c_x;
y = xy + xy + c_y;
}
count
}

The result of both Mandelbrot kernels, running in a loop with some printing code.
SIMD?
SIMD (Single Instruction Multiple Data) is a way to get data
parallelism on a lot of modern hardware: CPUs have instructions that
will operate on vectors of multiple values in a single call, e.g. most
x86 CPUs offer the addps and mulps instructions to do four
single-precision floating point additions (multiplications,
respectively) in parallel, by operating on two 128-bit registers.
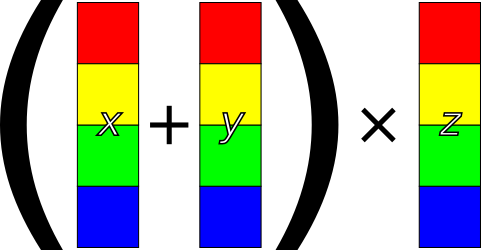
Rust is a good fit for many of the headline examples of such applications, which are traditionally written in C/C++ (or Fortran, for the last),
- media codecs (audio, video, images)
- games/things that do a lot of 3D graphics manipulation
- numerical software (data processing (big or not), simulations etc.)
Improved support for explicit SIMD enables Rust to reliably push hardware to its limit in these areas, and more.
Common vs. Platform-specific
There’s a common core of operations that is widely supported, however,
there is a variety of useful instructions that aren’t found
everywhere. My simd crate tries to provide a consistent API for the
cross-platform functionality, and then opt-ins for platform specific
things. The cross-platform API of simd is based on
work on SIMD in JavaScript: they’ve already done the hard
yards to abstract out a basic set of operations that generally work
efficiently, or are extremely useful, everywhere. It definitely
doesn’t cover everything, but it does go a long way.
A limited-but-increasing amount of the platform-specific functionality
is exposed via submodules of the simd crate, allowing one to opt-in
to non-portability in a manner similar to std::os. For
example, the SSSE3 instruction pshufb is exposed as the
shuffle_bytes method on traits in simd::x86::ssse3:
1
2
3
4
5
pub fn shuffle(x: u8x16, y: u8x16) -> u8x16 {
use simd::x86::ssse3::*;
x.shuffle_bytes(y)
}
Caveat Programmor: even the cross-platform API isn’t entirely portable
at the moment, it requires some level of SIMD support in hardware,
and requires the simd library to have support for the platform. The
major example of this is ARM and i686 (i.e. x86) CPUs aren’t
guaranteed to have SIMD instructions, so one must opt-in via the -C
target-feature=+neon (respectively -C target-feature=+sse2)
argument to the compiler0. Also, I haven’t worked on PowerPC or
MIPS, focusing only on x86, ARM and AArch64 (ARMv8-A’s 64-bit
architecture).
Benchmarks
Does this help? Yes! SIMD code in Rust can be several times faster
than scalar code, and is comparable and even ahead of using the
intrinsics in Clang. GCC seems to still have a significant edge over
Rust/LLVM (rustc’s optimiser) in some cases, but not in others.
I wrote a collection of microbenchmarks comparing the new SIMD functionality to scalar Rust code, and to similar implementations in C/C++:
- operations on 4×4
f32matrices (only SIMD Rust vs. scalar Rust)- inversion
- multiplication
- transposition
- the Mandelbrot example above
- some benchmarks from the Benchmark Game, where the fastest
programs use explicit SIMD:
- nbody (fastest on single-core x86-64 is C)
- fannkuch-redux (C++)
- spectral-norm (C)
I adapted the inverse and multiply comparative benchmarks from
ecmascript_js into Rust microbenchmarks, and
translated the fastest benchmark game programs into Rust. I used the
original implementations of those fastest programs for comparison and
the fastest Rust programs (none of which use explicit SIMD) as a
baseline, after disabling threading. All of this Rust code is
included as examples or benchmarks in
the simd repository.
The Rust code is quite portable. The matrix operations use only the
cross-platform API and so work on x86, ARM and AArch64 right now. The
nbody and spectral-norm benchmarks require f64s (aka doubles)
which are only supported by x86-64 & AArch64 hardware. The
fannkuch-redux benchmark requires conditionally defining a single
operation based on the platform, which takes only a few lines on each
listed platform.
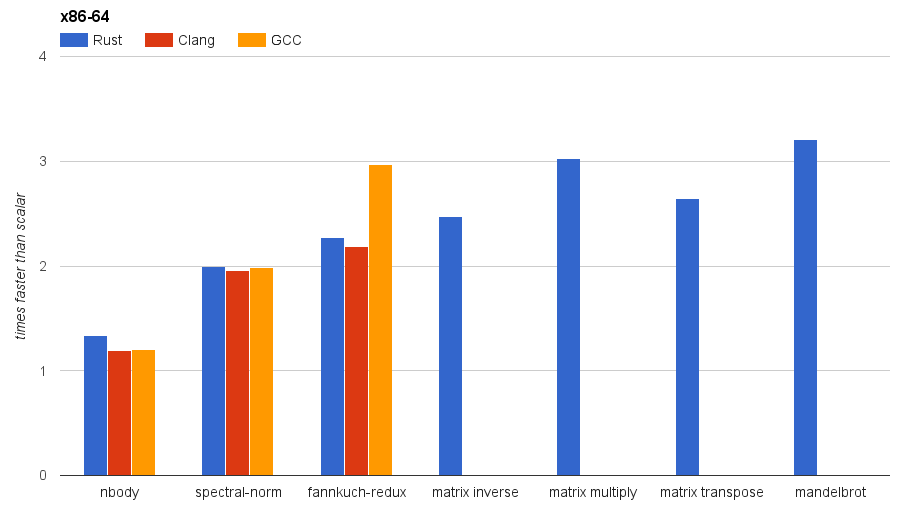
Benchmarks on x86-64 (Intel i7-4900MQ). The Rust code was compiled with -C opt-level=3, the C/C++ with -O3. SSSE3 was enabled for fannkuch-redux only.
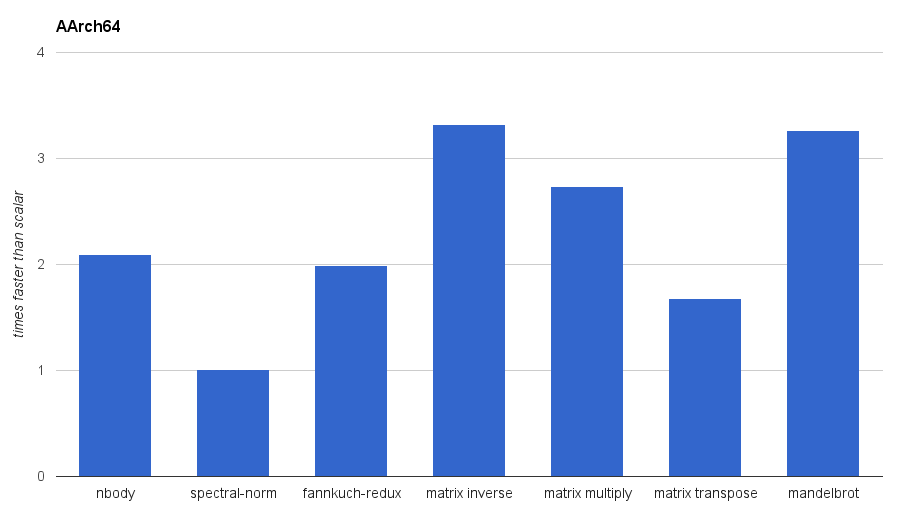
Benchmarks on AArch64 (Google Nexus 9). The Rust code was compiled with -C opt-level=3.
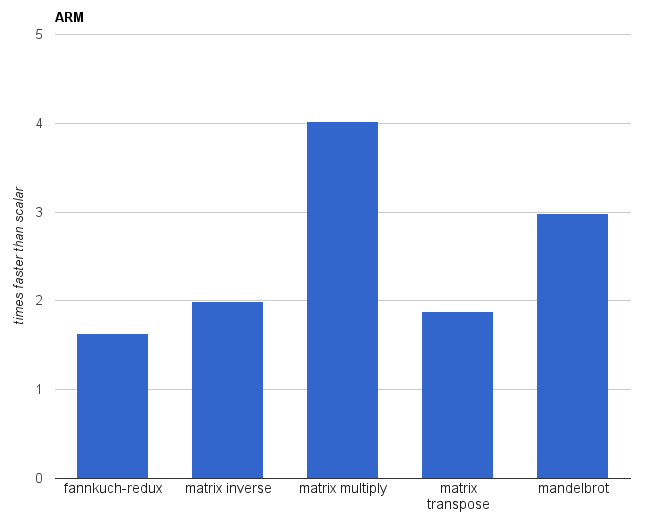
Benchmarks on ARM (Google Nexus 5). The Rust code was compiled with -C opt-level=3 -C target-feature=+neon.
Compiler versions:
rustc 1.4.0-dev (02e97342c 2015-08-17)Ubuntu clang version 3.6.0-2ubuntu1 (tags/RELEASE_360/final) (based on LLVM 3.6.0)gcc (Ubuntu 4.9.2-10ubuntu13) 4.9.2
Explicit SIMD in the Compiler
My changes are a large incremental improvement over the old SIMD
support in Rust. Previously, the only explicit SIMD supported by the
compiler was declaring types as SIMD vectors with the #[simd]
attribute, which automatically allowed the use of built-in operators
like + and * and (sometimes) ==. This was the full extent, and
the only way to get anything beyond that was by relying on the
optimiser, using inline assembly or horrible hacks. Now,
there are a large number of intrinsics defined by the compiler as
foreign functions with a special ABI. The simd crate imports them to
implement its functionality, e.g.:
1
2
3
4
5
6
7
#[repr(simd)]
struct u8x16(u8, u8, u8, u8, u8, u8, u8, u8,
u8, u8, u8, u8, u8, u8, u8, u8);
extern "platform-intrinsic" {
fn x86_mm_shuffle_epi8(x: u8x16, idx: u8x16) -> u8x16;
}
These intrinsics follow the pattern of
<architecture>_<vendor's-name>, relying on the definitions that CPU
vendors give.
Speaking of the optimiser, rustc uses LLVM, which is industrial
strength, and supports a lot of autovectorisation1: compiling
scalar code into code that uses SIMD intrinsics. The power of this can
be seen above in the spectral-norm benchmark on AArch64, where the
optimiser managed to make the scalar code just as efficient as the
vector code. However, this is limited: small code changes can disturb
vectorisation optimisations, and, more significantly, vectorisation
may require changing the semantics slightly, and, synthesising
complicated vector instructions is hard for a compiler2.
The new compiler intrinsics brings Rust essentially on par with the
SIMD extensions in C and C++ compilers like GCC, Clang and ICC. It
requires some more manual effort to use it directly, with manual
extern imports required, but libraries like simd avoid that issue.
The Future
The goal for the immediate future is nailing down the design of the low-level functionality discussed in RFC 1199, and making sure that the initial implementation in #27169 matches that. An unfortunate missing piece is nice support for rearranging vectors via shuffles and swizzles: I believe it requires RFC 1062 or some other way to have values in generics3.
My long-term goal is to have simd provide the common cross-platform
API, with extension traits giving access to all of the
platform-specific instructions. All of this will have as thin an
interface to as possible: the vast majority of functions correspond to
one instruction. (One question I haven’t resolved is what to call
these functions: I could name them directly after the instruction they
correspond to (pshufb), or after the equivalent C intrinsic
(_mm_shuffle_epi8), or something approximately descriptive
(shuffle_bytes). Thoughts?)
I’m not personally planning to build long-vector functionality on top of the improved short-vector functionality, but it is certainly something that would be very cool to see.
One major missing piece of this new SIMD support in Rust is how to handle run-time determination of SIMD functionality: it’s relatively common to have an algorithm with multiple implementations for different levels of SIMD support, with a run-time switch to choose the fastest one supported by the CPU being used. For example, x86-64 CPUs are only guaranteed to support SSE2, but there’s things beyond that with more functionality and even longer SIMD vectors (Intel’s new AVX512 has 512-bit vectors). I’ve got some vague ideas in this area, but nothing concrete yet.
- users
- /r/rust
-
Passing the
-C target-featureflag to a whole compilation withcargois somewhat annoying at the moment. It requires a custom target spec or intercepting howrustcis called via theRUSTCenvironment variable (for my own experiments, I’m doing the latter: pointing the variable to a shell script that runsrustc -C target-feature='...' "$@"). This is covered by #1137. ↩ -
LLVM by itself isn’t as powerful as Intel’s ISPC, which has its own C variant, but I could imagine a Rust version too, to push the limits of compiler-driven autovectorisation (among other things) here too. ↩
-
Another thing compilers can’t easily do is layout optimisations. A major one is an AoS (array-of-structs) to SoA (struct-of-arrays) transformation, which is particularly important for SIMD, both explicit and autovectorised. ↩
-
Fortunately, not all is lost: I’ve always seen the optimiser synthesise a real shuffle from a manual series of
extracts and anew. It’s annoying and isn’t strictly guaranteed, but it seems to be pretty reliable. ↩